Mario Carrion









Disclaimer: This post includes Amazon affiliate links. If you click on one of them and you make a purchase I’ll earn a commission. Please notice your final price is not affected at all by using those links.
Welcome to another post part of the series covering Concurrency Patterns in Go, this time I’m talking about the Pipeline pattern.
What is the Pipeline pattern?
According to Wikipedia, a Pipeline:
…consists of a group of processing elements arranged so the output of each element is the input of the next one.
In Go this is equivalent to implementing functions that receive a channel and return another channel for another function to consume, typically each function will mutate the results in a way those are useful for the subsequent steps.
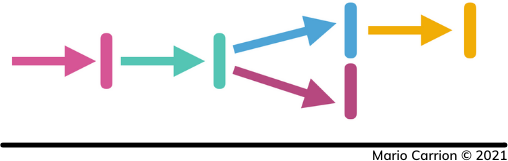
For example in a program that consists of multiple steps, they could be implemented in such a way the output of the initial step is the input of the next one; however one thing to keep in mind is that this doesn’t mean those steps should be sequential but rather they only branch off depending on how the program needs to implemented.
When building pipelines consider that the slowest step in your process will determine how fast or slow everything will be; so in some cases it could make sense to also apply a different concurrency pattern to the branched off step, recall to always benchmark.
Pipeline Concurrency Pattern Example
The code used for this post is available on Github.
The following example (errors omitted for brevity):
1func main() {
2 recordsC, _ := readCSV("file1.csv")
3
4 for val := range sanitize(titleize(recordsC)) {
5 fmt.Printf("%v\n", val)
6 }
7}
Will read a CSV file and apply some logic to each value read, it consists of:
- L2: We read a CSV file, the result is a channel
recordsC. - L4: We use
recordsCas the input oftitleizeandsanitize
The function titleize:
1func titleize(strC <-chan []string) <-chan []string {
2 ch := make(chan []string)
3
4 go func() {
5 for val := range strC {
6 val[0] = strings.Title(val[0])
7 val[1], val[2] = val[2], val[1]
8
9 ch <- val
10 }
11
12 close(ch)
13 }()
14
15 return ch
16}
- L2:
chchannel is created (it will be used as the input for the next pipeline step) - L4-13: Uses a goroutine to:
- L5: Receive the values from the channel
strC, - L6-7: Transform those values by Titleizeing them and switching them, and
- L9: Sends the changes to the channel
ch - L12: After the
foris completed, then channelchis closed to indicate the indicate the end of this pipeline step.
- L5: Receive the values from the channel
- L15:
chchannel is returned.
Implementation-wise the function sanitize is a bit similar to the previous one:
1func sanitize(strC <-chan []string) <-chan []string {
2 ch := make(chan []string)
3
4 go func() {
5 for val := range strC {
6 if len(val[0]) > 3 {
7 fmt.Println("skipped ", val)
8 continue
9 }
10
11 ch <- val
12 }
13
14 close(ch)
15 }()
16
17 return ch
18}
The biggest difference would be the actual logic applied to the received values:
- L6-9: Where we skip any value that as length longer than 3.
If you recall main we have the pipeline call using both those functions:
sanitize(titleize(recordsC))
Now if this is changed to be something like:
titleize(sanitize(recordsC))
As expected, the output will change, because now the sanitize happens before titleize; but the functions still behave as steps in our pipeline.
Conclusion
Pipeline is a well-known concurrency pattern that is easy to implement in Go and allow us to use the primitives of the language to describe the steps a in concurrent way, however, before implementing it in your programs make sure each step is benchmarked so you have a baseline for comparing your changes, typically using goroutines improves the performance of our programs, but in some cases it could make things worse.
Recommended reading
If you’re looking to sink your teeth into more Go-related topics I recommend the following:
- Get Programming with Go
- Learning Go: Introduction to Concurrency Patterns
- Learning Go: Fan-In and Fan-Out Concurrency Pattern
- Learning Go: Concurrency Patterns using errgroup package