Mario Carrion









Disclaimer: This post includes Amazon affiliate links. If you click on one of them and you make a purchase I’ll earn a commission. Please notice your final price is not affected at all by using those links.
Welcome to another post part of the series covering Quality Attributes / Non-Functional Requirements, this time I’m talking about a Cloud Design Pattern to improve Scalability and Security called: Throttling.
What is Throttling?
Throttling is a way to limit access to resources by a period of time. Defining how to limit those resources depend on concrete use cases, for example we could be limiting by user id, by application name or really don’t make a differentiation at all and throttle all requests coming into our service.

Throttling is a way to improve Scalability because it allows our current services to handle spikes of load without failing, while Elasticity kicks-in; and also a way to improve Security because it can allow us to detect requests from the same origin that probably could lead to use excessive resources.
Monetization is also another reason for using Throttling but really that is not a Quality Attribute / Non-functional Requirement, but still it’s another use case you can consider for using this pattern.
How does Throttling work?
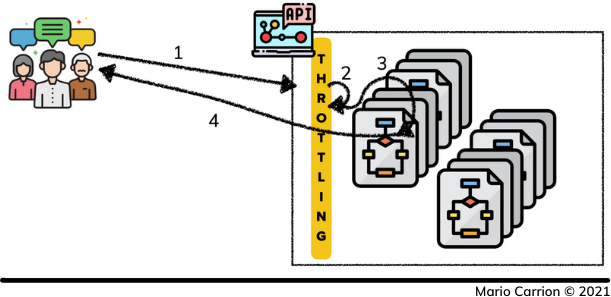
In the most basic form Throttling consists of keeping track of how many times a resource is accessed by a concrete user, the way we define a user depends on our user case, it could be based on IP Address, Headers or even resource paths.
- User requests a resource,
- Throttling layer determines if it’s allowed to continue,
- It allows the request to continue, and finally
- Returns back the result to the user.
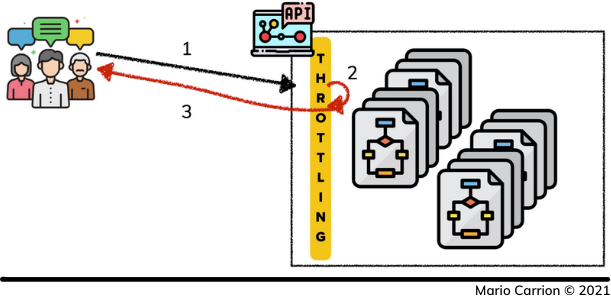
In cases where Throttling was already triggered the steps are simplified:
- User requests a resource,
- Throttling layer determines it’s not allowed to continue and it’s blocked, and finally
- Returns back an error message to the user.
How can Throttling be implemented in Go?
The code used for this post is available on Github.
In Go there are multiple packages implementing Throttling, to mention a few:
The one I’m using for this post is the one implemented in the package didip/tollbooth, it’s easy to use and already implements a middleware that can be added to an HTTP handler, one important thing regarding this package is that it does not support persistent store, so different HTTP Servers behind a Load Balancer can’t share throttling details.
Using it is really simple:
lmt := tollbooth.NewLimiter(3, &limiter.ExpirableOptions{DefaultExpirationTTL: time.Second})
lmtmw := tollbooth.LimitHandler(lmt, r)
And then using it as a handler in your HTTP server:
return &http.Server{
Handler: lmtmw, // Using handler throttling requests!
Addr: conf.Address,
ReadTimeout: 1 * time.Second,
ReadHeaderTimeout: 1 * time.Second,
WriteTimeout: 1 * time.Second,
IdleTimeout: 1 * time.Second,
}, nil
Conclusion
The Throttling pattern improves Scalability because it allows to stop processing requests when non-malicious “spiky”-loads happen, it also improves Security in cases where malicious users try to intentionally overload our services.
Recommended reading
If you’re looking to sink your teeth into more Software Architecture-related topics I recommend the following links:
- Quality Attributes / Non-Functional Requirements
- Agile Software Development, Principles, Patterns, and Practices
- Building Evolutionary Architectures: Support Constant Change
- Hands-On Software Architecture with Golang