Mario Carrion









What is Kafka?
Kafka is an event streaming platform, it allows us to publish, subscribe, store and process events. An Event indicates something that happened, if we use our To Do Microservice as example, we could define events to indicate a TaskCreated or TaskUpdated when a Task is created or when a Task is updated, respectively.
How does Kafka work?
In Kafka there’s a concept called Topic, Topics store events published by a Publisher; those Topics can be named for to differentiate between them and they can be Partitioned, what this means is that they could be separated into multiple Kafka brokers, or instances in charge of storing the topics, defining various partitions allows scaling Kafka to allow multiple publishers and consumers to write and read data.
When an event is published to a Topic it will be stored in order it was received, this allows the Consumers to read those events in the same order they were published:
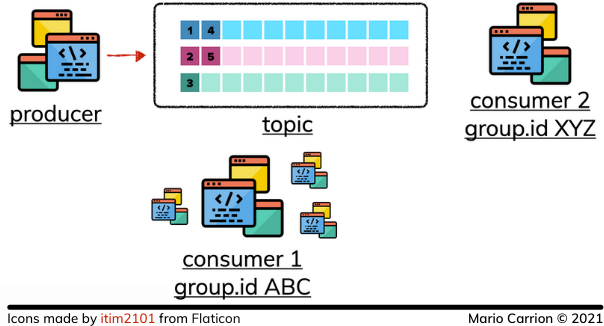
Consumers use Group IDs to identify themselves when reading events that way multiple processes can consume the same topic in a way the events are still consumed in order:
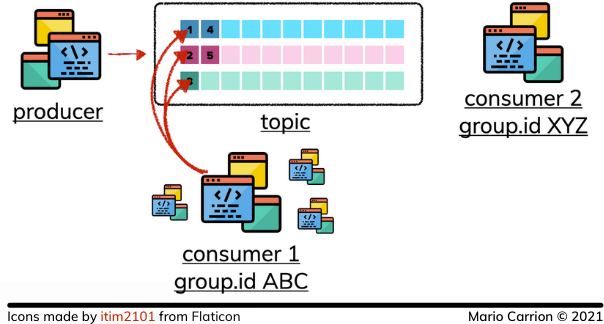
Because of those Group IDs, multiple processes can read the same data at a different pace of speed without affecting other consumers:
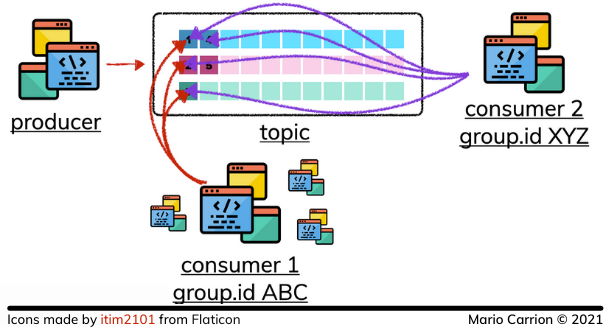
Publisher implementation using a Repository
The code used for this post is available on Github.
For communicating with Kafka we are going to use the official package confluentinc/confluent-kafka-go and similar to other Repositories we implemented previously a new package will be defined called kafka.
This package will implement the corresponding Task in charge of publishing the events that represent the actions executed when Tasks change to indicate creation, deletion and updates.
The code looks like this:
func (t *Task) Created(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Created", "tasks.event.created", task)
}
func (t *Task) Deleted(ctx context.Context, id string) error {
return t.publish(ctx, "Task.Deleted", "tasks.event.deleted", internal.Task{ID: id})
}
func (t *Task) Updated(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Updated", "tasks.event.updated", task)
}
Those exported methods use an unexported method called publish that interacts directly with the Kafka Producer, the event to be sent will be encoded using encoding/json, the idea is to define a JSON payload that then our Consumers can use for determine what event to use, more in the section below covering Consumers:
func (t *Task) publish(ctx context.Context, spanName, routingKey string, e interface{}) error {
// XXX: Excluding OpenTelemetry and error checking for simplicity
var b bytes.Buffer
evt := event{
Type: msgType,
Value: task,
}
_ = json.NewEncoder(&b).Encode(evt)
_ = t.producer.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{
Topic: &t.topicName,
Partition: kafka.PartitionAny,
},
Value: b.Bytes(),
}, nil)
return nil
}
To connect this Kafka repository with the PostgreSQL repository we will update each method in service.Task to call the corresponding publish-related method, for example:
func (t *Task) Create(ctx context.Context, description string, priority internal.Priority, dates internal.Dates) (internal.Task, error) {
// XXX: Excluding OpenTelemetry and error checking for simplicity
task, _ := t.repo.Create(ctx, description, priority, dates)
// XXX: Transactions will be revisited in future episodes.
_ = t.msgBroker.Created(ctx, task) // XXX: Ignoring errors on purpose
return task, nil
}
Refer to the original code to see how the other methods were updated to do something similar.
For consuming the events we will define a new program that will be using the same topic to read the data we published, and then it will update the Elasticsearch values using that repository.
Consumer implementation
Like I mentioned above the new program will consume the Kafka events and depending on the event type it will call the corresponding Elasticsearch method to reindex the values; this program also supports Graceful shutdown.
The program uses the Consumer to poll the values that represent the events to read, the simplified code looks like:
for run {
msg, ok := s.kafka.Consumer.Poll(150).(*kafka.Message)
if !ok {
continue
}
var evt struct {
Type string
Value internaldomain.Task
}
_ = json.NewDecoder(bytes.NewReader(msg.Value)).Decode(&evt)
switch evt.Type {
case "tasks.event.updated", "tasks.event.created":
// call Elasticsearch to index record
case "tasks.event.deleted":
// call Elasticsearch to delete record
}
}
When building your final program consider implementing a Server-like type, with the goal of separating the different received events into their corresponding types, that way your switch could be replaced with a map of functions pointing to the “handlers” of each type being consumed.
Conclusion
Kafka is a powerful platform for dealing with events, it could be used as a message broker to distribute information across multiple services but it also supports storing and replaying events as well as analysis of those events they are received.
Recommended Reading
If you’re looking to do something similar in RabbitMQ and Redis, I recommend reading the following links:
- Microservices in Go: Events and Background jobs using RabbitMQ
- Microservices in Go: Using Pub/Sub with Redis