Mario Carrion









What is RabbitMQ?
RabbitMQ is a message-queueing software also known as a message broker or queue manager. It supports protocols such as AMQP, MQTT and STOMP, to name a few. RabbitMQ could be used for long-running tasks, for example background jobs, and for communication between different services.
How does RabbitMQ work?
The easiest analogy to describe RabbitMQ is that of a Post Office and the required steps involved, from beginning to end, to deliver a mail to the final destination. In real life those steps consist of dropping off the mail into a mailbox, then some processing behind the scenes to route that mail and finally a mail person brings that mail to the destination.
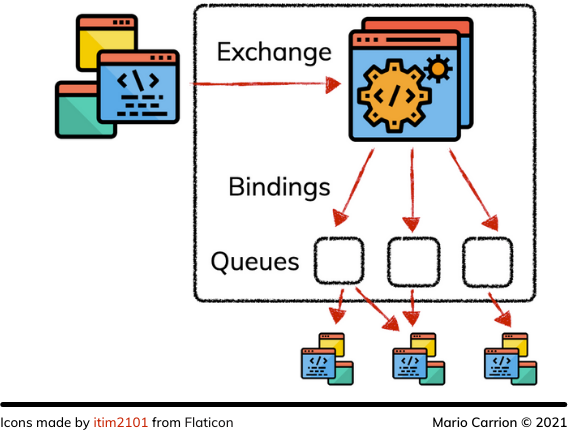
RabbitMQ works as a queue where Publishers can submit messages which then are eventually consumed by multiple Consumers; however the interesting part about RabbitMQ is the intermediary mechanism that sits between those publishers and consumers. This intermediary is called Exchange, this Exchange can be configured to define Bindings to allow those messages to be routed into different Queues which then the clients can listen to for consuming messages in different ways, to perhaps consume by a only concrete key or a wildcard.
Publisher implementation using a Repository
The code used for this post is available on Github.
To interact with RabbitMQ we will use the package streadway/amqp and similar to other data stores we will be defining a Repository that will be interacting with the actual RabbitMQ publisher and will be called in the service type.
This repository type will be named rabbitmq.Task, it will contain an unexported field referencing a RabbitMQ channel and the corresponding methods required for emitting three events Created, Deleted and Updated:
func (t *Task) Created(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Created", "tasks.event.created", task)
}
func (t *Task) Deleted(ctx context.Context, id string) error {
return t.publish(ctx, "Task.Deleted", "tasks.event.deleted", id)
}
func (t *Task) Updated(ctx context.Context, task internal.Task) error {
return t.publish(ctx, "Task.Updated", "tasks.event.updated", task)
}
Those three methods will refer to an unexported method called publish, which is used for publishing the data, this data is the result encoding the message using the encoding/gob package, similar to the code used when we discussed Caching with Memcached:
func (t *Task) publish(ctx context.Context, spanName, routingKey string, e interface{}) error {
// XXX: Excluding OpenTelemetry and error checking for simplicity
var b bytes.Buffer
_ = gob.NewEncoder(&b).Encode(e)
_ = t.ch.Publish(
"tasks", // exchange
routingKey, // routing key
false, // mandatory
false, // immediate
amqp.Publishing{
AppId: "tasks-rest-server",
ContentType: "application/x-encoding-gob",
Body: b.Bytes(),
Timestamp: time.Now(),
})
return nil
}
Next, in the service package the service.Task type is updated to receive an instance of that repository using an interface type, which then will be used it after the persistent datastore call is done, something like:
func (t *Task) Create(ctx context.Context, description string, priority internal.Priority, dates internal.Dates) (internal.Task, error) {
// XXX: Excluding OpenTelemetry and error checking for simplicity
task, _ := t.repo.Create(ctx, description, priority, dates)
_ = t.msgBroker.Created(ctx, task)
return task, nil
}
Please refer to the Delete call as well as the Update call for more details, in practice the code is similar to the one above.
Now, let’s take a look at the subscriber implementation. For this example we will implement a new running process in charge of consuming that data.
Subscriber implementation
This new process will consume those RabbitMQ events to properly index the Task records, changing the way we were using Elasticsearch originally, it will also support Graceful shutdown like we previously covered.
The code for listening, at the moment, is a slightly long method, the important part would be the actual Go channel returned by RabbitMQ, this code does something like the following to receive all events:
// XXX: Excluding some things for simplicity, please refer to the original code
for msg := range msgs {
switch msg.RoutingKey {
case "tasks.event.updated", "tasks.event.created":
// decode received Task event
// call Elasticsearch to index record
case "tasks.event.deleted":
// decode received Task event
// call Elasticsearch to delete record
}
// acknowledege received event
}
In a real-life implementation you should consider implementing a Server type able to handle different events, perhaps similar to the way net/http.Server works and maybe define something similar to a Muxer to allow listening to multiple events with their corresponding encoding/decoding logic.
Conclusion
RabbitMQ is commonly known as a distributed queue but it can also be used as a message broker to communicate multiple services, is a powerful tool that thanks to the available configuration options could serve to deliver messages to multiple clients at scale.
Recommended Reading
If you’re looking to do something similar in Kafka and Redis, I recommend reading the following links: