Mario Carrion









Long time ago I used to be a proponent of UML, I even started an open source project called MonoUML (already defunct). MonoUML was meant to, automatically, help developers to document their code using UML-based diagrams with little to no human intervention.
Sadly, I quickly realized that using UML was not the way to go, sure there are some great ideas and some useful diagrams but in the end there are way too many details to keep in mind to properly use this modeling language efficiently.
After moving on from UML I started using box and line diagrams, nothing fancy really and not standardized for sure, and that worked, however a few years ago I came across this model created by Simon Brown called C4 Model, C4 as in Context, Containers, Components, and Code.
C4 is sort of a slim UML where only the relevant data is presented to the user that happens to be interested in learning about the Software Architecture being described. What this means in practice is that the consumer of the diagram is who drives how much information is displayed, the official website uses this great analogy of Google Maps, where depending on what your goal is you will be presented with different detail maps.
The C4 Model defines four levels of diagrams:
- Context (L1): the highest level, it shows how the system relates to users and other systems. It is used as a quick introduction to the system, usually meant to be presented to stakeholders, this is the big picture diagram.
- Container (L2): breaks down the system into interrelated containers, containers are executable and deployable sub-systems. It is meant to be shared with people that need more technical details about how the system is composed.
- Component (L3): takes the containers and decomposes them into interrelated components, relates them to other containers or other systems. It is meant to be read by engineers not familiar with the system that are planning to work on it.
- Code (L4): provides more details about how the actual code is being implemented. It is meant to clearly display some concrete details about the most complex pieces of the system.
After using the C4 model for a couple of years already I’ve found those four levels more than enough to describe complex Software Architectures, I’ve found practical to implement the first three levels only, and leave the fourth level as the actual code that the engineers need to review and understand.
Caveats
With everything documentation-related there are always caveats, documenting Software Architectures is no different. In this case these caveats are presented in the form of questions: When?, How? and Who?
- When should we update the documentation?
- How should we update the documentation?
- Who should update the documentation?
Those three questions are hard to answer in isolation without enough details about the team trying to implement this model, this is because they depend on the team itself and the existing tools and processes they follow.
Ideally this documentation is updated by the team working on the system, this makes sense because they are really close to the changes being implemented. Usually teams using Infrastructure as a Code as part of the system being built, maybe using CloudFormation for AWS or maybe something for generic like Terraform, have less of a hard time keeping those documents updated because updating infrastructure details reminds the author to also revisit the documentation if needed.
In practice I haven’t found a way to enforce changes like those when committing a change into the repository, there’s no linter for those yet.
The recommended guideline for all team members is to keep in mind that diagrams should be updated when making new changes that affect anything related to any of those different levels.
Example
The following is a concrete example using the hypothetical Book Store System I introduced last time during my video Go Tools: counterfeiter (blog link). This time the system will be extended a bit more, and as usual the complete code of this example is available on my Gitlab repository.
Let’s start with the Context Diagram.
Context Diagram
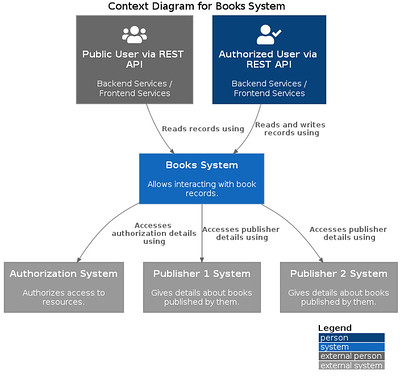
This diagram is more than enough when trying to convey three details we need to share with our stakeholders about our Books System:
- It has two different types of users: Public and Authorized,
- Depends on an external Authorization System for authorization purposes, and
- Depends on two external systems Publisher 1 System and Publisher 2 System for catalog purposes
Next, the Container Diagram.
Container Diagram
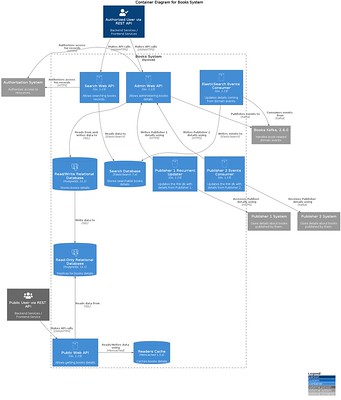
This diagram zooms in to mention more technical details about the actual system, it explicitly indicates the technologies we use, like Go, PostgreSQL, ElasticSearch and Kafka; and depending on the technology being used it calls out the concrete containers in charge of handling that work, specifically we see (left to right, top to bottom):
- Search Web API: HTTP handlers, use ElasticSearch as the Search Database for searching read-only records,
- Admin Web API: HTTP handlers, use PostgreSQL as the Read/Write Relational Database for administering records,
- ElasticSearch Events Consumer: binary listening to Kafka domain events for updating the Search Database on demand,
- Publisher 1 Recurrent Updater: binary that runs every X amount of time in charge of importing data from Publisher 1, it uses the Admin Web API for updating that data,
- Publisher 2 Events Consumer: binary listening to external events coming from Publisher 2 System using Kafka, it uses the Admin Web API for updating that data, and
- Public Web API: HTTP handlers, use the PostgreSQL Read-Only Retailer Database for getting read-only records.
Finally, the Component Diagram
Component Diagram - Admin Web API
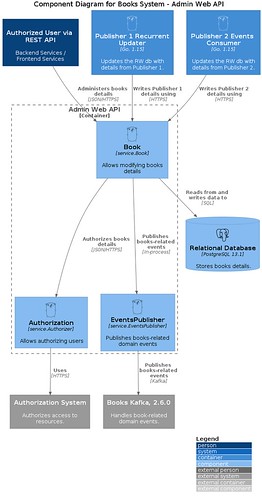
The last diagram I cover this time is the concrete component diagram for the Admin Web API, keep in mind if you look at the list above there are six containers, we may want to implement all of them or some of them depending on how complex they are; in this case I’m only implementing this one but the idea should be the same when implementing the other five.
This diagram zooms in even more to describe concrete containers and how the interaction happens with each other, the goal is to give engineers more details about how things are implemented, for example indicate what concrete package or types are in charge of the work being done.
Conclusion
I find the C4 Model better than UML for documenting software architectures, however the problems we have had for years are still there, specifically the questions I mentioned in the beginning, at the moment there is no way to enforce updating diagrams when making changes to the actual code or the infrastructure.
Engineers should keep an eye out when making those changes and react accordingly, this is easier said than done and it may take a while to get the team used to, but this should be the initial step when trying to keep the documentation up to date.